Abstract
Large Language Models (LLMs) and Vision-Language Models (VLMs) increasingly generate indoor scenes through intermediate structures such as layouts and scene graphs, yet evaluation still relies on LLM or VLM judges that score rendered views, making judgments sensitive to viewpoint, prompt phrasing, and hallucination. When the evaluator is unstable, it becomes difficult to determine whether a model has produced a spatially plausible scene or whether the output score reflects the choice of viewpoint, rendering, or prompt. We introduce SceneCritic, a symbolic evaluator for floor-plan-level layouts. SceneCritic's constraints are grounded in SceneOnto, a structured spatial ontology we construct by aggregating indoor scene priors from 3D-FRONT, ScanNet, and Visual Genome. SceneCritic traverses this ontology to jointly verify semantic, orientation, and geometric coherence across object relationships, providing object-level and relationship-level assessments that identify specific violations and successful placements. Furthermore, we pair SceneCritic with an iterative refinement test bed that probes how models build and revise spatial structure under different critic modalities: a rule-based critic using collision constraints as feedback, an LLM critic operating on the layout as text, and a VLM critic operating on rendered observations. Through extensive experiments, we show that (a) SceneCritic aligns substantially better with human judgments than VLM-based evaluators, (b) text-only LLMs can outperform VLMs on semantic layout quality, and (c) image-based VLM refinement is the most effective critic modality for semantic and orientation correction.
Motivation

Our motivation is to solve the research question: Are VLM evaluators robust to hallucinations and prompt-phrasing? Can VLM-evaluators handle view-bias? Is Human Evaluation the solution? The follow-up question is: Are Human evaluations scalable? We are excited to present SceneCritic, a symbolic evaluator for floor-plan-level layouts grounded in SceneOnto data.
SceneOnto Dataset
- Dimensions: Object geometry constraints using percentile statistics (p5, p25, median, p75, p95, mean, std) for width, height, and depth, along with corresponding sample counts.
- Room Associations: Captures how frequently each object category appears across different room types, storing both absolute counts and normalized fractions relative to total observations.
- Support Surfaces: Records the surfaces on which objects are typically placed (e.g., floor, shelf), mapping each surface type to its count and fraction.
- Co-occurrence: Models object co-occurrence patterns by mapping each category pair to statistics including co-occurrence count, conditional probability (p_b_given_a), and normalized pointwise mutual information (npmi). Entries are sorted by frequency and capped at 50.
- Co-occurrence by Room: Extends co-occurrence statistics by conditioning on room type, providing up to 50 entries per room for finer contextual relationships.
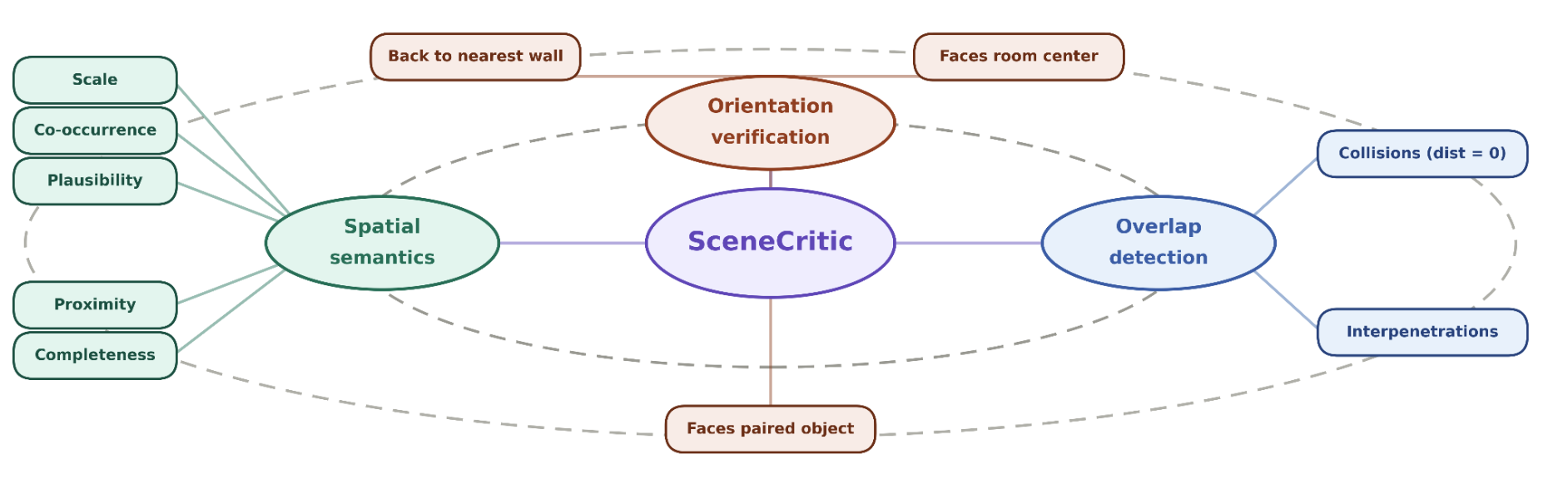
- Orientation Relationships: Consists of three sub-components:
- Back to Wall: Fraction of instances whose back direction aligns with the nearest wall (within 45°), along with mean angular deviation and sample count.
- Faces Center: Fraction of instances oriented toward the room centroid (within 60°).
- Faces Pair: Pairwise facing relationships, mapping categories to the fraction of instances facing them (within 60°), along with mean angle, mean distance, and sample count.
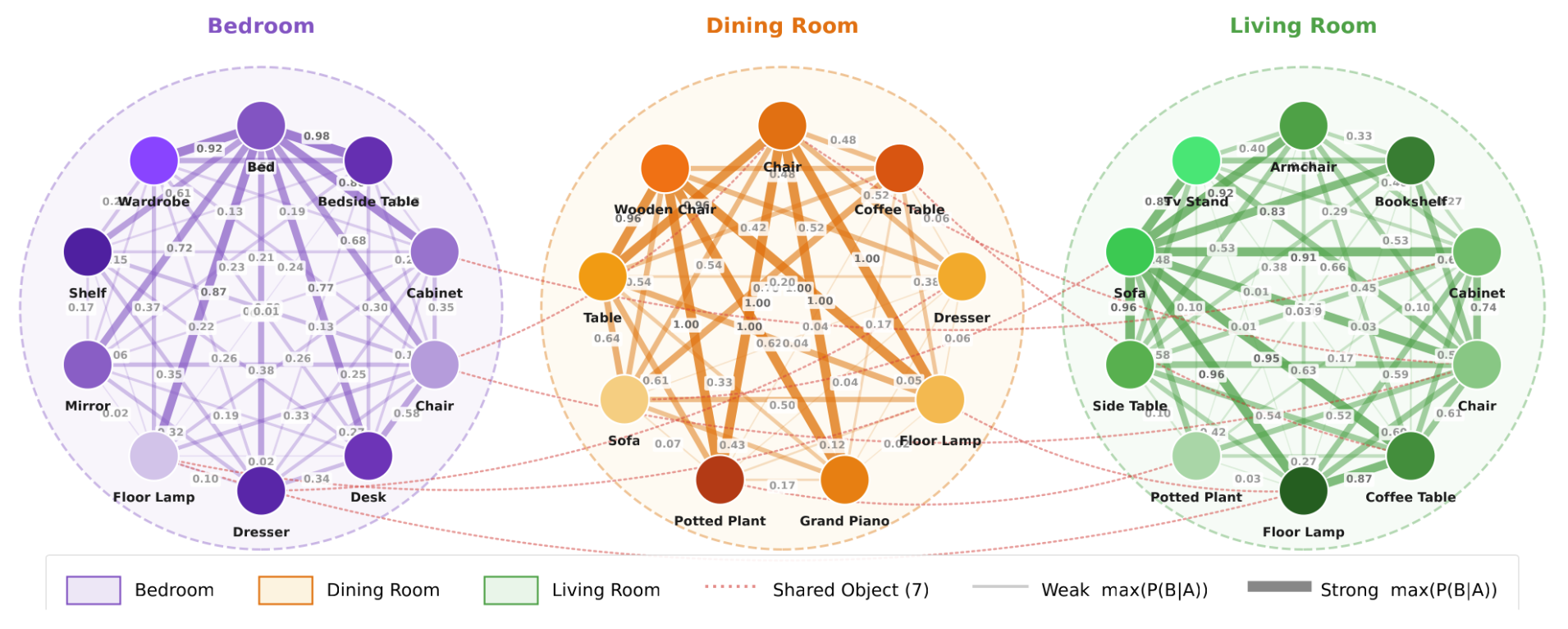
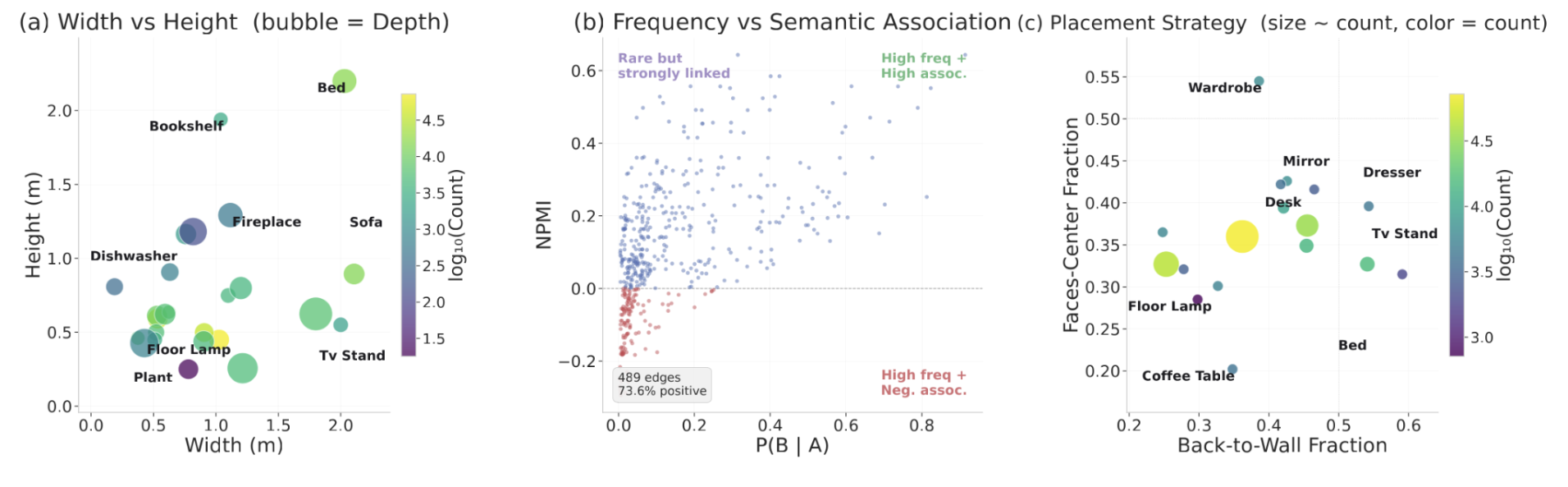
SceneCritic
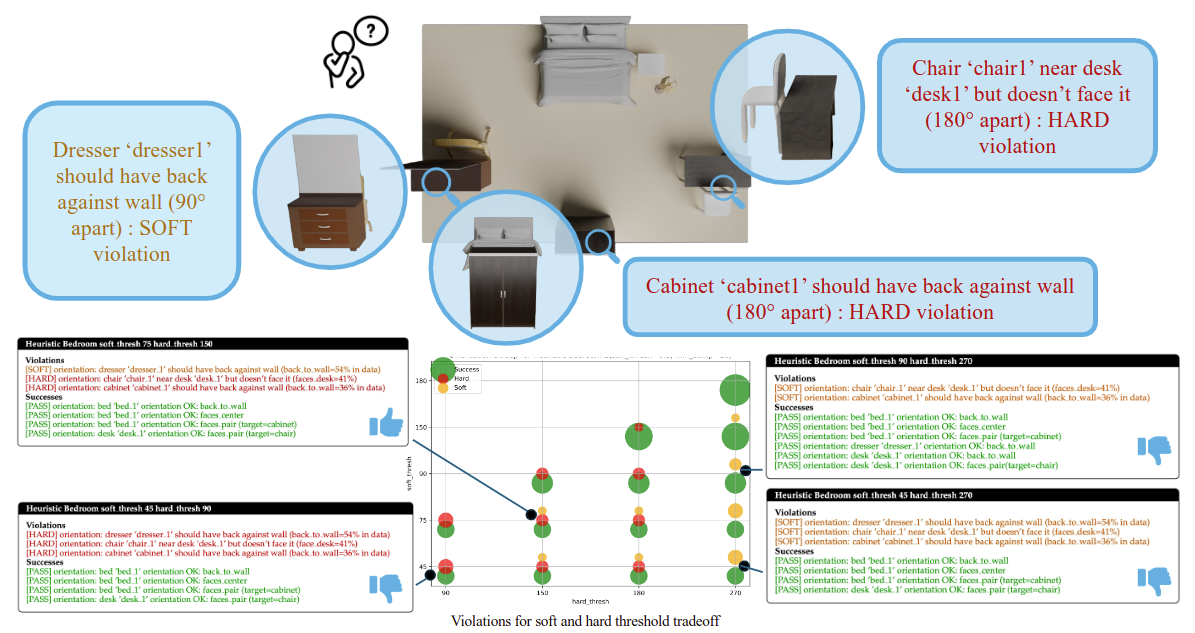
SceneCritic Ablation Study
We ground the hyperparameter tuning in Procthor-10K dataset, a procedurally generated 3D scene dataset. We verify the hyperparameters by comparing human analysis with evaluation by SceneCritic with Procthor grounded hyperparameters. The figure above shows a typical room analysis.
Results
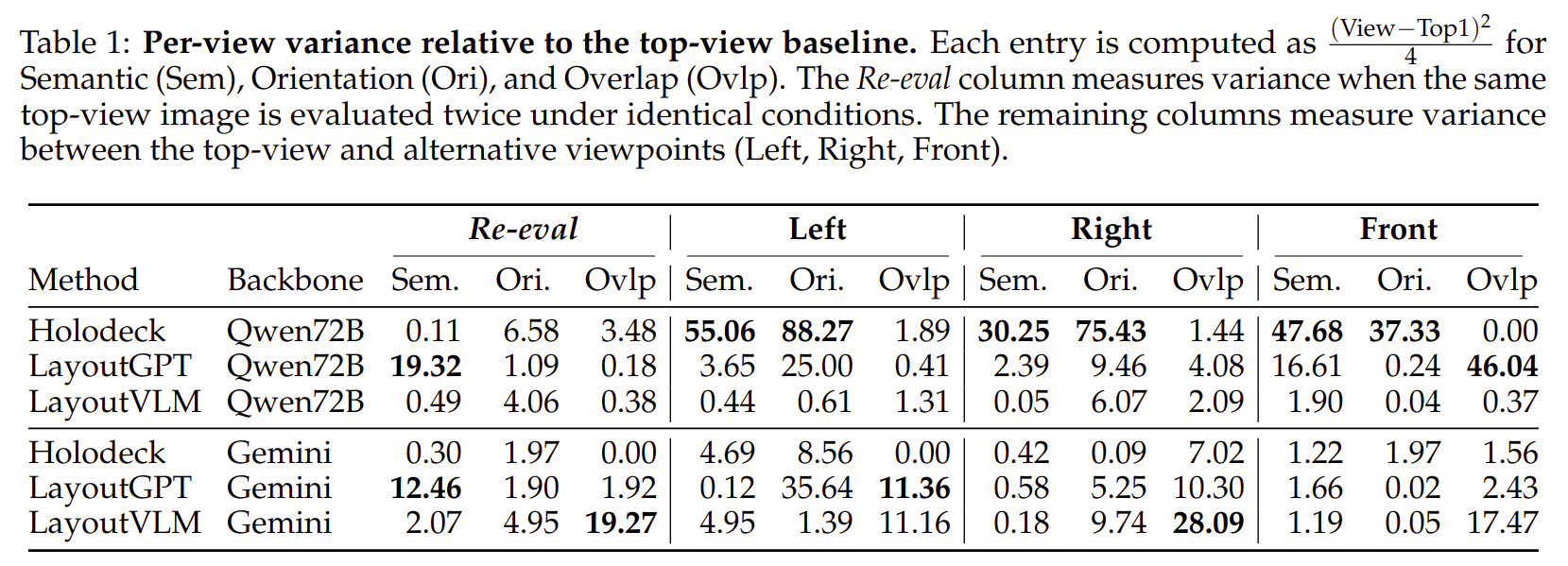
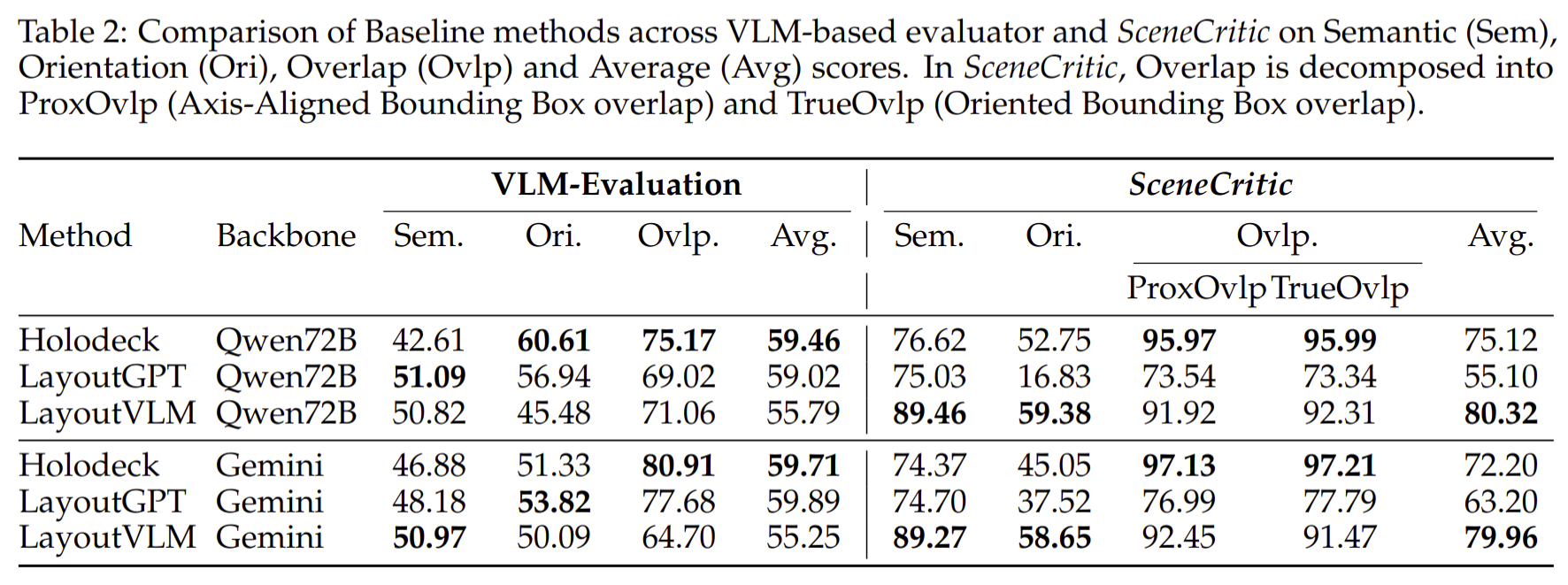
Human Evaluators Agreement
- Easy Room Configurations:
- SceneCritic: 94.44%
- VLM Evaluation: 58.82%
- Complex Room Configurations:
- SceneCritic: 83.33%
- VLM Evaluation: 40%
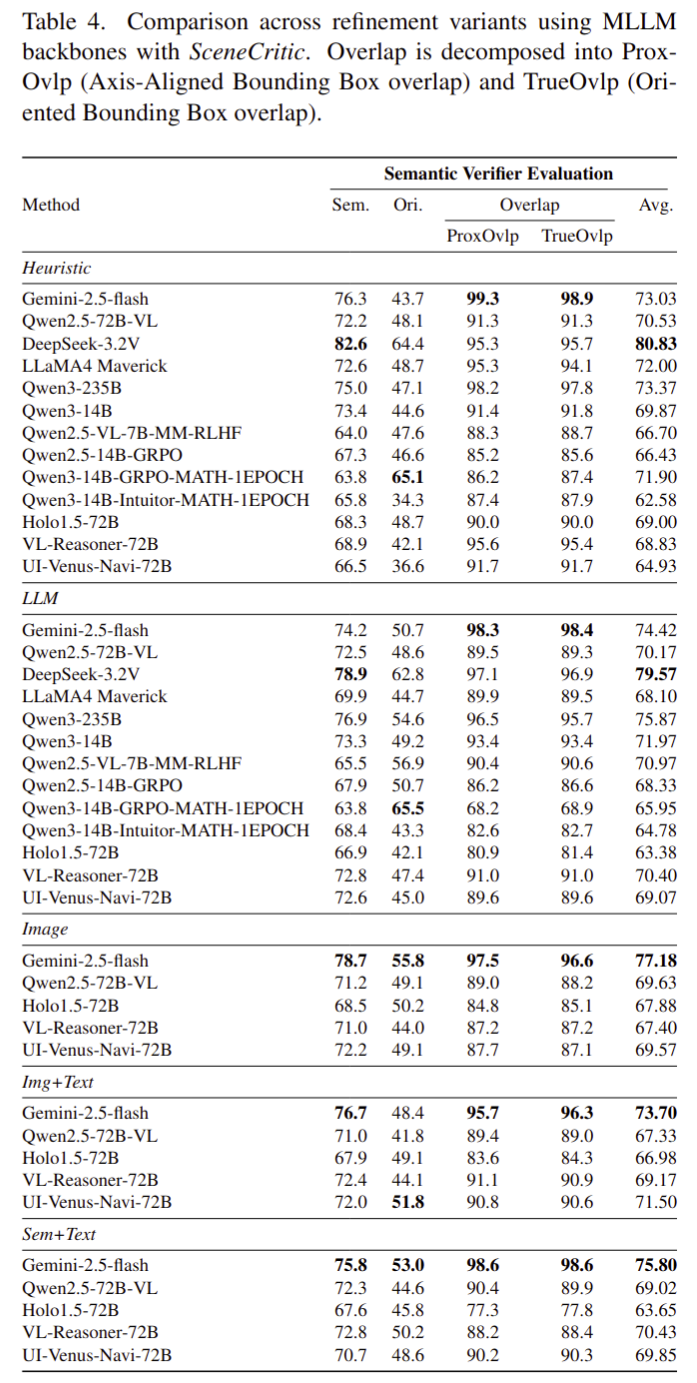
- Text-only LLMs(Deepseek-3.2v) can outperform VLMs (Gemini-2.5-Flash) on spatial reasoning.
- Orientation is the most challenging metrics.
- Image-based (visual) refinement is the most effective critic modality for layout generation improvement.